centos安装kafka
安装java
java -version
su -c "yum install java-1.8.0-openjdk"
选择合适的版本,到镜像站下载kafka
安装与使用可参考官方文档:kafka-doc
> wget http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz
> tar -xzf kafka_2.11-2.0.0.tgz
> cd kafka_2.11-2.0.0
解压到特定路径使用-C参数:tar -xzf kafka*.tgz -C youdir
建议修改数据及日志文件的路径:grep -Iri dir ./config/
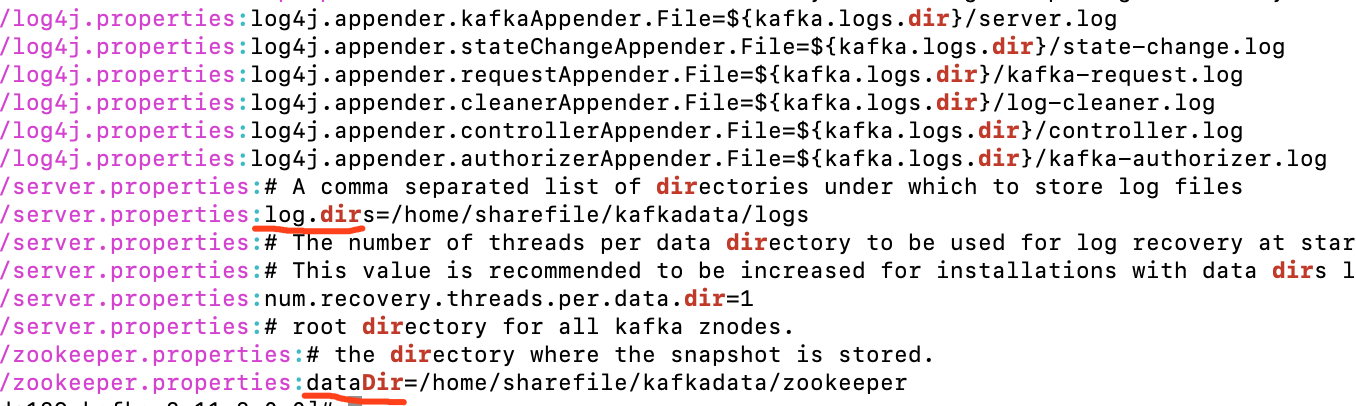
zk的dataDir默认路径为/tmp,会被系统定时清理,容易造成topic丢失。
如果需要修改log4j的日志路径,编辑文件:vim bin/kafka-server-start.sh
在开头增加一项:export LOG_DIR=/home/sharefile/kafkadata/log4j
kafka的配置需要注意listeners与advertised.listeners。客户端会先连接到listeners地址,然后通过dvertised.listeners获取元数据。如果后者没有配置会使用前者地址,如果都没有配置会使用主机名或者localhost。一般只需要配置前者:listeners=PLAINTEXT://:0.0.0.0:9092
启动和测试
> bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
> bin/kafka-server-start.sh -daemon config/server.properties
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
> bin/kafka-topics.sh --list --zookeeper localhost:2181
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
使用 -daemon参数可以在后台运行,去掉后可调试运行。
查看group-id
cat config/consumer.properties |grep "group"
python的client推荐
- 纯python实现,相当pythonic,5星推荐:kafka-python
- librdkafka的包装器,4星推荐:confluent-kafka-python
- librdkafka的包装器,4星推荐:pykafka
使用kafka-python测试生产者:pip install kafka-python
from kafka import KafkaProducer
import time
producer = KafkaProducer(bootstrap_servers='192.168.1.143:9092')
for _ in range(10):
msg = time.strftime("%Y-%m-%d %H:%M:%S")
future = producer.send('mytopic',msg.encode('utf-8'))
result = future.get(timeout=10)
print(result)
producer.flush()
测试消费者
from kafka import KafkaConsumer
# 不同group_id会收到全量数据,相同group_id会去负载均衡数据
consumer = KafkaConsumer('mytopic',bootstrap_servers='192.168.1.143:9092',group_id='mygoupid')
#consumer.seek_to_beginning() # 从头开始
for msg in consumer:
print(msg.value.)
查看最新的offset
bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic test --time -1
参考