大话大数据
一、大数据的前世今生 计算机的基础避不开4大问题:数据输入、计算、存储 、查询。大数据技术本质上就是在大量计算机构成的结构中解决这4个核心问题。
最需要解决这个问题的是Google,
在一个夜黑风高的晚上,江湖第一大帮会Google三本阵法修炼秘籍流出,大数据技术江湖从此纷争四起、永无宁日…这三本秘籍分别为:《Google file system》:论述了怎样借助普通机器有效的存储海量的大数据;《Google MapReduce》:论述了怎样快速计算海量的数据;《Google BigTable》:论述了怎样实现海量数据的快速查询;
但是。。。
谷歌只写了论文,自己开发的系统不开源。
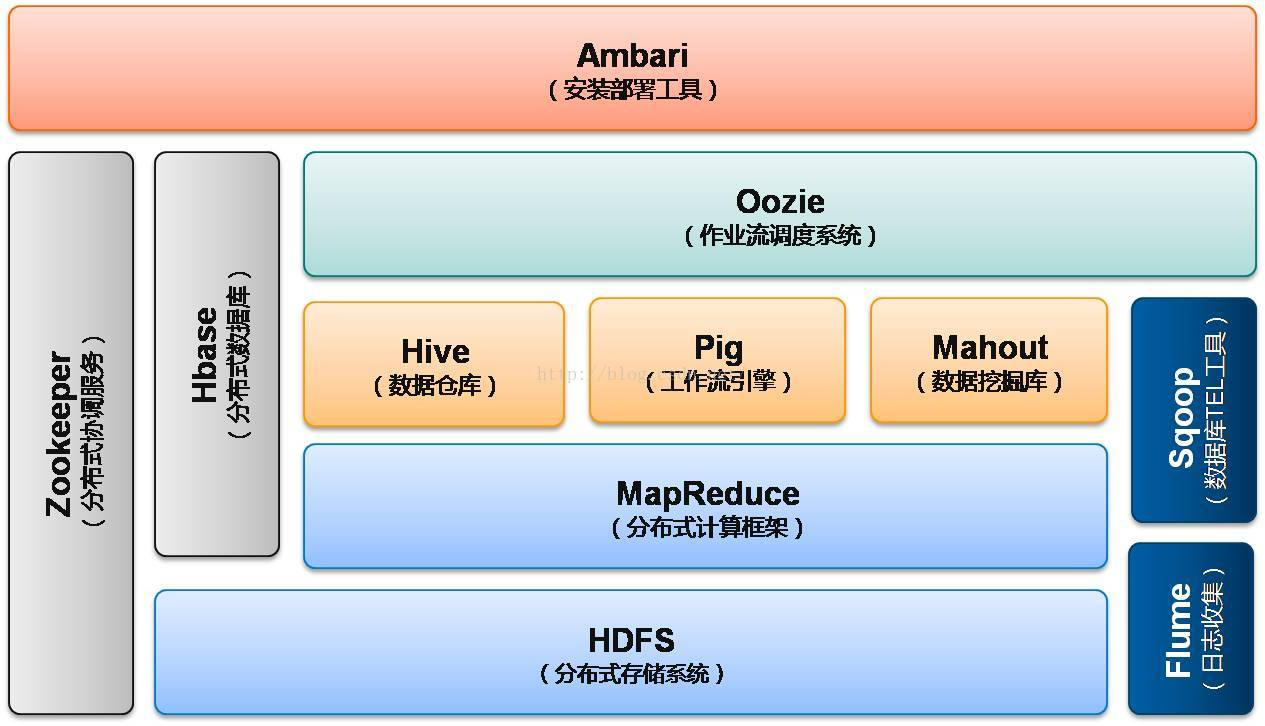
开源届的第一大帮会apache登场,根据这三本秘籍分别研究出了对应的武学巨著《hadoop》,并开放给各大门派研习,Hadoop包括三大部分,分别是hdfs、MapReduce和hbase:hdfs解决大数据的存储问题。mapreduce解决大数据的计算问题。hbase解决大数据量的查询问题。
之后在各大门派的支持下,Hadoop不断衍生和进化各种分支流派,其中最激烈的当属计算技术,其次是查询技术。存储技术基本无太多变化,hdfs一统天下。
以下为大概的演进:
查询派(想写个东西写好几百行):mapreduce相当于汇编语言,虽然强大万能但查个东西得一天。推了hive,pig、impla等SQL ON Hadoop简易修炼秘籍,以前写几百行代码现在只需要写三五行,从此在大数据里纵享丝滑。
离线计算优化派(想算个东西等到你哭):mapreduce太过复杂且计算超级缓慢,于是推出基于内存的《Spark》,意图解决所有大数据计算问题。
实时计算派(有的东西不想要重复计算):hadoop只能憋大招(批量计算),太麻烦,于是出了SparkStreaming、Storm,S4等流式计算技术,能够实现数据一来就即时计算。
apache:看各大门派纷争四起,推出flink,想一统流计算和批量计算的修炼。(话外,阿里拿flink来操练发现部分不太适合随后推出修改版blink)
大数据的关键技术原理 HDFS(Hadoop Distributed FileSystem):与传统的文件系统如fat32/ntfs基于单机工作不同,fdfs的本质上是为了大量的数据能横跨成百上千台机器而设计。/hdfs/xxx高清.mp4
MapReduce:现有有一gexxx.txt超大文档,你想知道这些个档里的每个单词出现的频率。先map:去每个机器上取txt并计算词频,然后reduc:汇总计算各个机器上的词频,最后得到整个文件的词频结果。
周边派:
最后上一张hadoop组件生态
二、大数据平台的演化路径
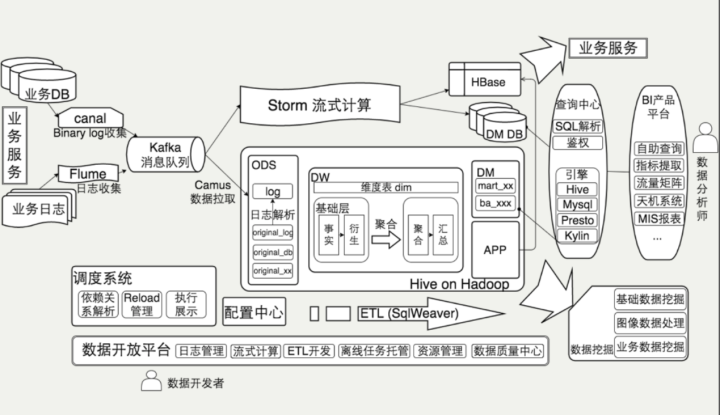
参考其他公司
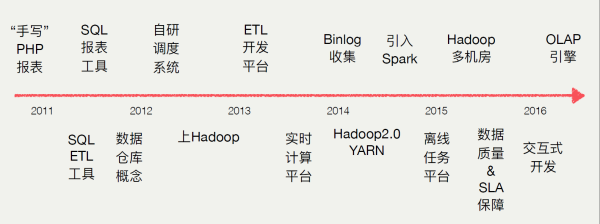
参考